Acknowledgements
We deeply thank our collaborators from the following academic and industrial institutions:
In recent years, large language models (LLMs) have been widely adopted in political science tasks such as election prediction, sentiment analysis, policy impact assessment, and misinformation detection. Meanwhile, the need to systematically understand how LLMs can further revolutionize the field also becomes urgent. In this work, we--a multidisciplinary team of researchers spanning computer science and political science--present the first principled framework termed Political-LLM to advance the comprehensive understanding of integrating LLMs into computational political science. Specifically, we first introduce a fundamental taxonomy classifying the existing explorations into two perspectives: political science and computational methodologies. In particular, from the political science perspective, we highlight the role of LLMs in automating predictive and generative tasks, simulating behavior dynamics, and improving causal inference through tools like counterfactual generation; from a computational perspective, we introduce advancements in data preparation, fine-tuning, and evaluation methods for LLMs that are tailored to political contexts. We identify key challenges and future directions, emphasizing the development of domain-specific datasets, addressing issues of bias and fairness, incorporating human expertise, and redefining evaluation criteria to align with the unique requirements of computational political science. Political-LLM seeks to serve as a guidebook for researchers to foster an informed, ethical, and impactful use of Artificial Intelligence in political science.
Political science is broadly defined as the study of political systems, behavior, institutions, and policy-making processes, aiming to understand how power and resources are distributed within societies. It relies on diverse forms of political data, including legislative documents, political speeches, public opinion surveys, and news reports, which serve as the foundation for political analysis. Traditionally, political science relied heavily on qualitative methods, such as content analysis and case studies, alongside quantitative approaches like statistical modeling and surveys, to examine trends and patterns in political behavior. These methods, while foundational, often faced challenges in scaling, handling multilingual and unstructured data, and deriving insights from vast corpora of text. The emergence of LLMs has helped overcome these hurdles by enabling automated, large-scale analysis of political data, providing researchers with unprecedented tools to process and interpret political texts more effectively. In particular, LLMs have been critical in analyzing extensive corpora of political texts, encompassing a wide range of sources such as political speeches, legislative documents, social media content, and news articles. Through these practices, LLMs have enabled stakeholders such as researchers and policy makers to gain an in-depth understanding of various facets such as political behavior, public opinion, policy formulation, and latest election dynamics.

For instance, LLMs are revolutionizing how we handle complex legislation, such as contract analysis and redlining. By leveraging advanced AI capabilities, LLM tools can significantly enhance efficiency and accuracy in legislative-related workflows. Statistical data show that with the support of LLM tools, a staff can Redline contracts 10X faster, compare provisions against market standards for every clause, summarize core and discrete differences between a counterparty's contract and your gold standard effortlessly.
See the LLM-based legislation tool in action below:
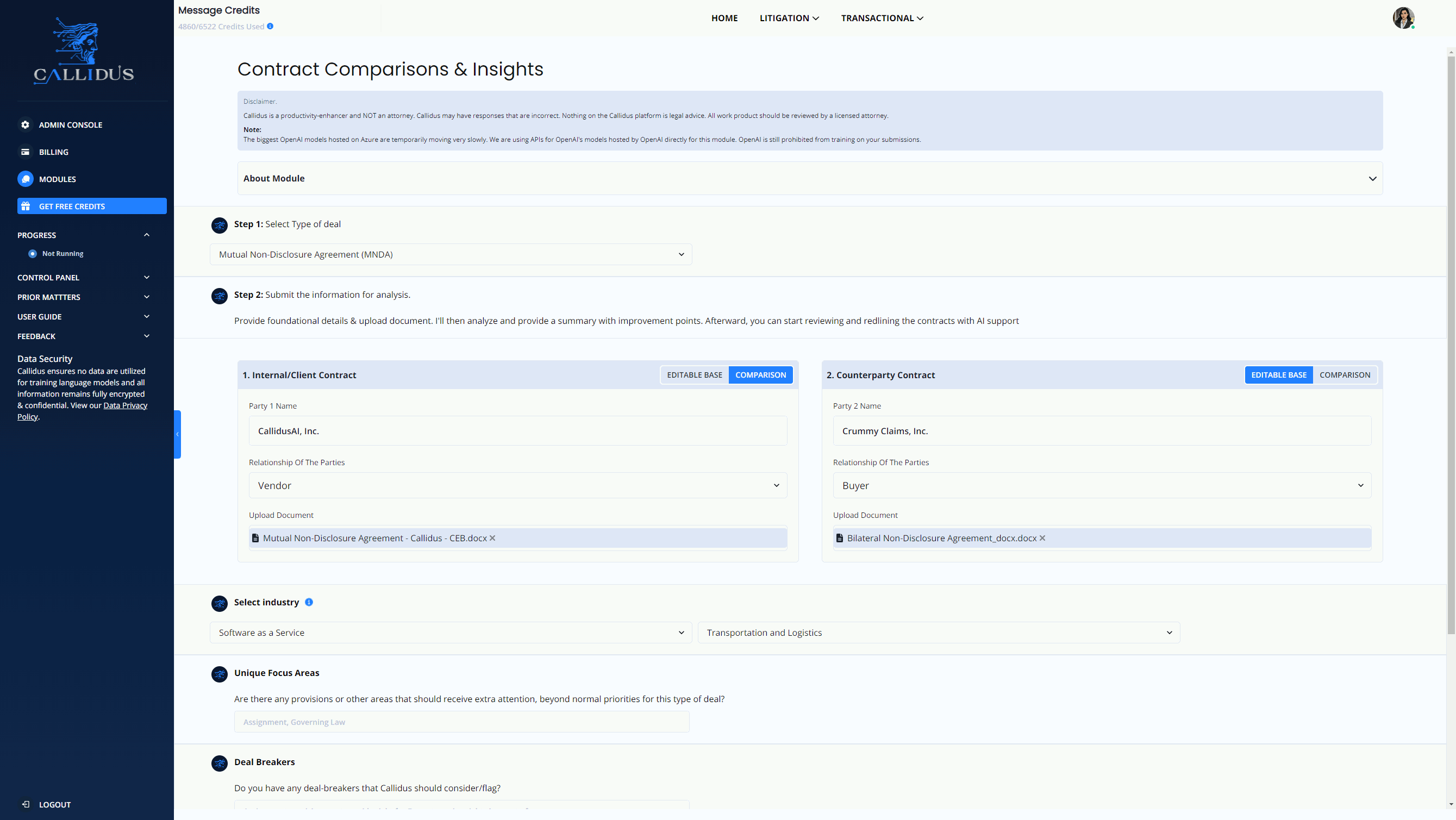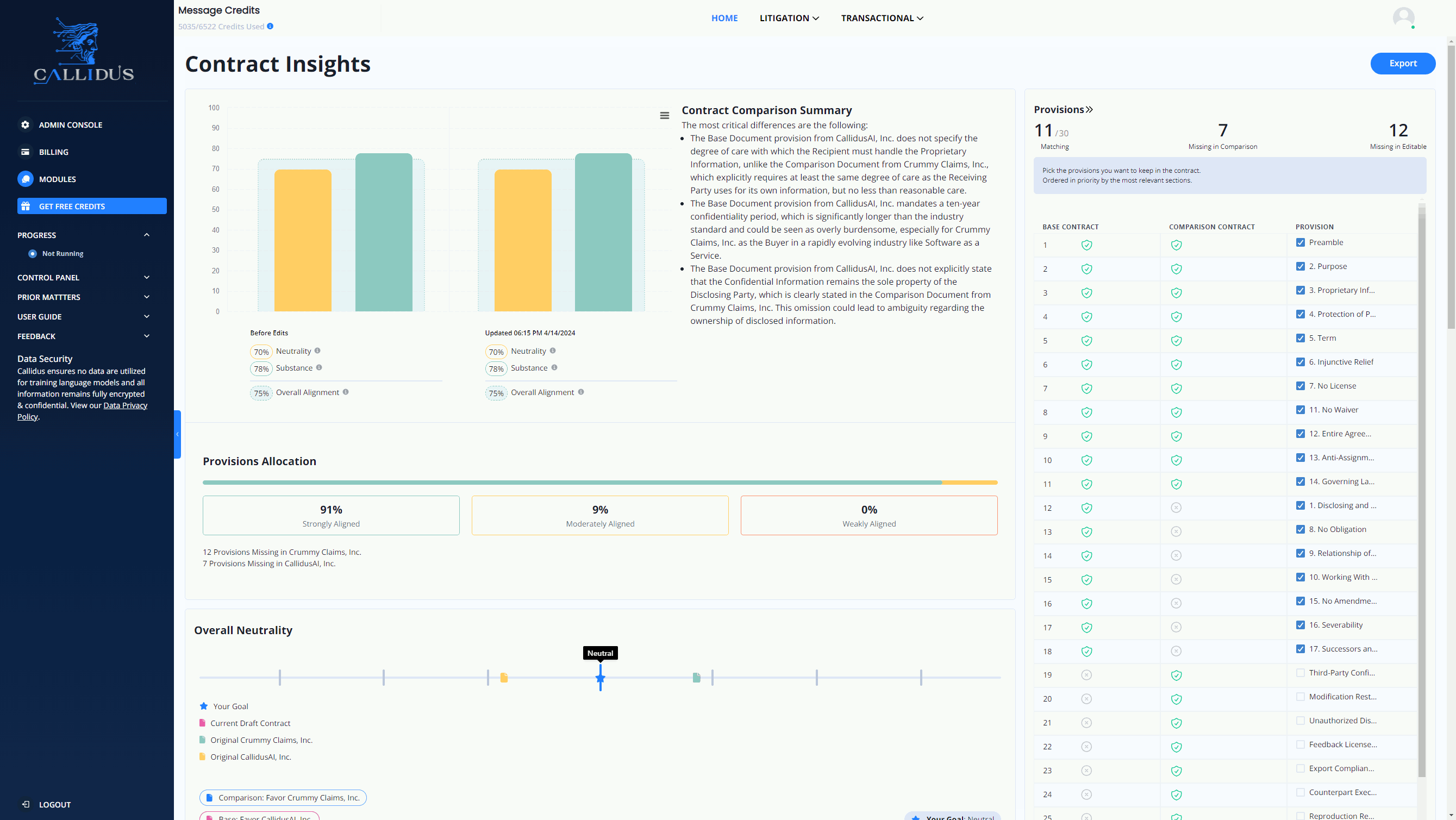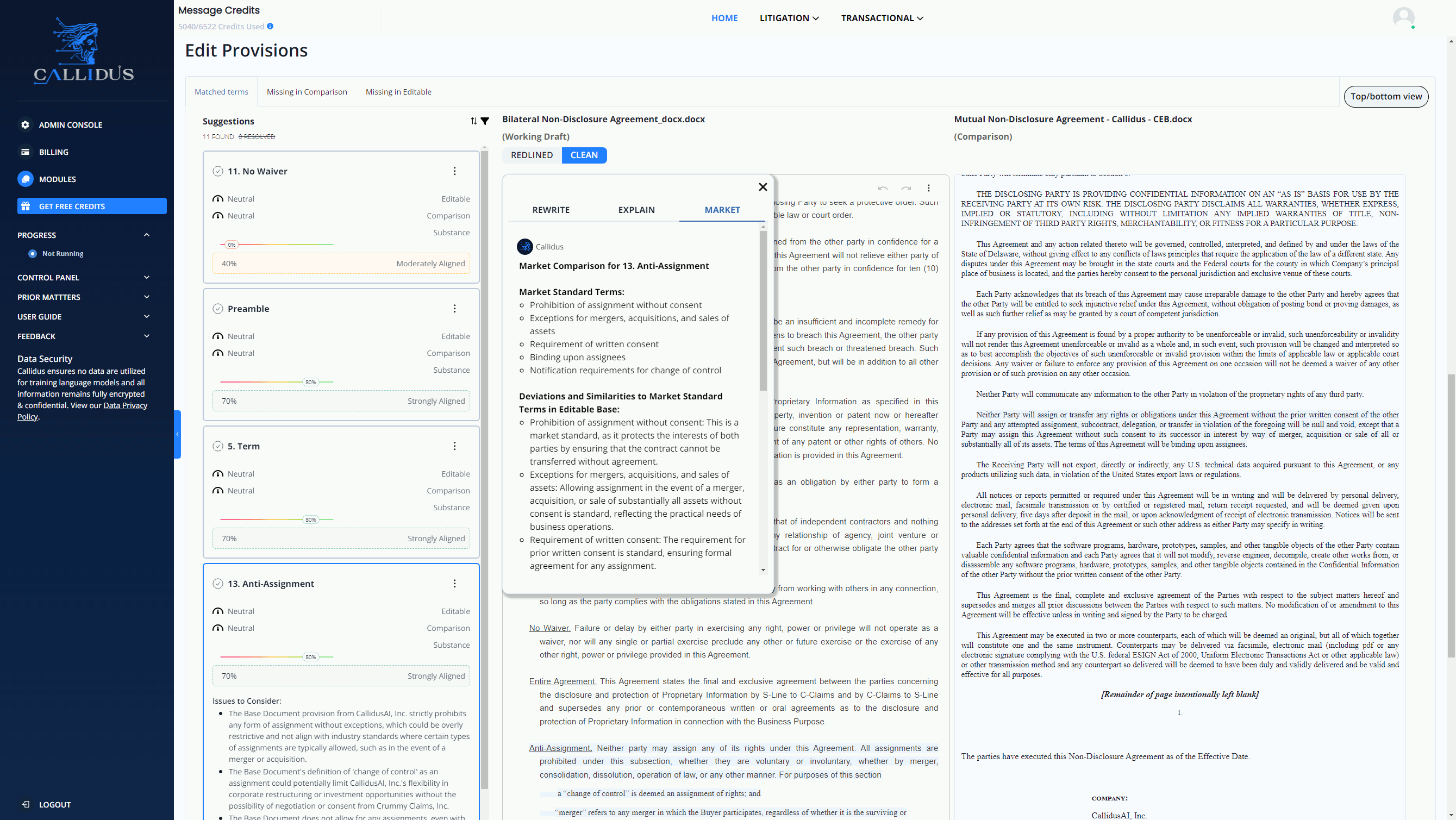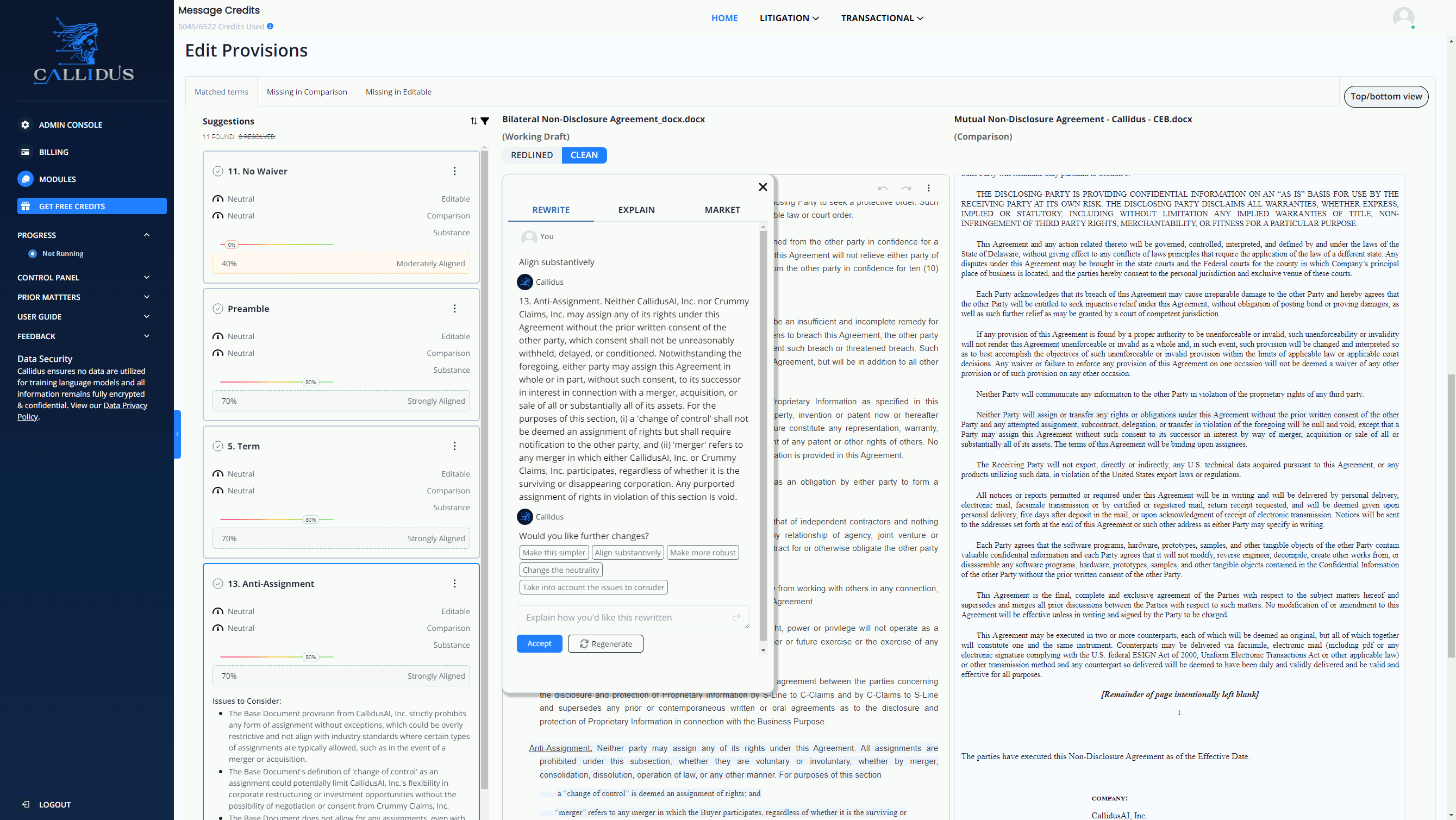
Image Source: https://www.callidusai.com
However, significant gaps hinder their full potential in political science. These include a lack of systematic frameworks for adapting LLMs to political research, technical challenges like bias and privacy concerns, and insufficient integration of domain-specific knowledge. Addressing these gaps requires interdisciplinary collaboration to enhance the utility, precision, and contextual relevance of LLMs in this field, paving the way for robust research and applications.
In this research, we aim to provide the first comprehensive overview of adapting LLMs in political science (PoliSci), addressing key challenges and guiding future research directions. We introduce a novel taxonomy to classify methods and applications systematically, aiding researchers in navigating the field. The research explores advancements in adapting LLMs to political tasks, tackling challenges like societal biases, hallucinations, and privacy concerns.
we further examine PoliSci LLMs' training and inference methodologies standing from computer science perspective, utilizing curated datasets, various fine-tuning and efficient inference techniques for enhanced performance. Finally, we provide real-world applications, such as presidential election prediction and misinformation detection, concluding with research outlooks for this interdisciplinary field.
The main contributions of this survey paper could be summarized as:
Here is how our survey is different from existing ones:
| Ziems et al., 2024 | Argyle et al., 2023 | Ornstein et al., 2022 | Rozado, 2023 | Weidinger et al., 2021 | Linegar et al., 2023 | Lee et al., 2024 | Ours | |
|---|---|---|---|---|---|---|---|---|
| Proposed Taxonomy on LLM for PoliSci | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔ |
| Review from PoliSci Perspective | ✔ | ❌ | ✔ | ❌ | ❌ | ✔ | ✔ | ✔ |
| Review from CS Perspective | ❌ | ❌ | ✔ | ❌ | ✔ | ✔ | ❌ | ✔ |
| Structured Analysis of CPS Methodologies | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔ |
| Include Experiments & Evaluations | ✔ | ✔ | ✔ | ✔ | ❌ | ❌ | ✔ | ✔ |
| Application Examples | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Comprehensive Summary of Benchmarks | ✔ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔ |
| Limitation and Challenge Analysis | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Future Research Direction | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ❌ | ✔ |
*Abbreviations: PoliSci = Political Science, CPS = Computational Political Science, CS = Computer Science
Here are some essential preliminaries to guide you through our research. Click on these buttons below to view their detailed explanations.
This taxonomy categorizes the integration of LLMs in political science into two areas: political science tasks and computational approaches. Tasks include predictive tasks, generative tasks, simulation, causal inference, and social impacts. Predictive tasks use LLMs to analyze public opinion, electoral outcomes, and policies, while generative tasks synthesize political data, such as summarizing legislation and debates. Simulations model political behaviors, reducing costs and improving efficiency. Causal inference identifies relationships and counterfactuals, offering insights into causality and bias. Social impacts examine campaign strategies and ethical considerations. Computational approaches comprise benchmark datasets, data processing, fine-tuning, zero/few-shot inference, and advanced techniques like retrieval-augmented generation and chain-of-thought reasoning. These methods ensure reliability, address bias, and optimize LLMs for nuanced political applications, forming a comprehensive framework for political science research.
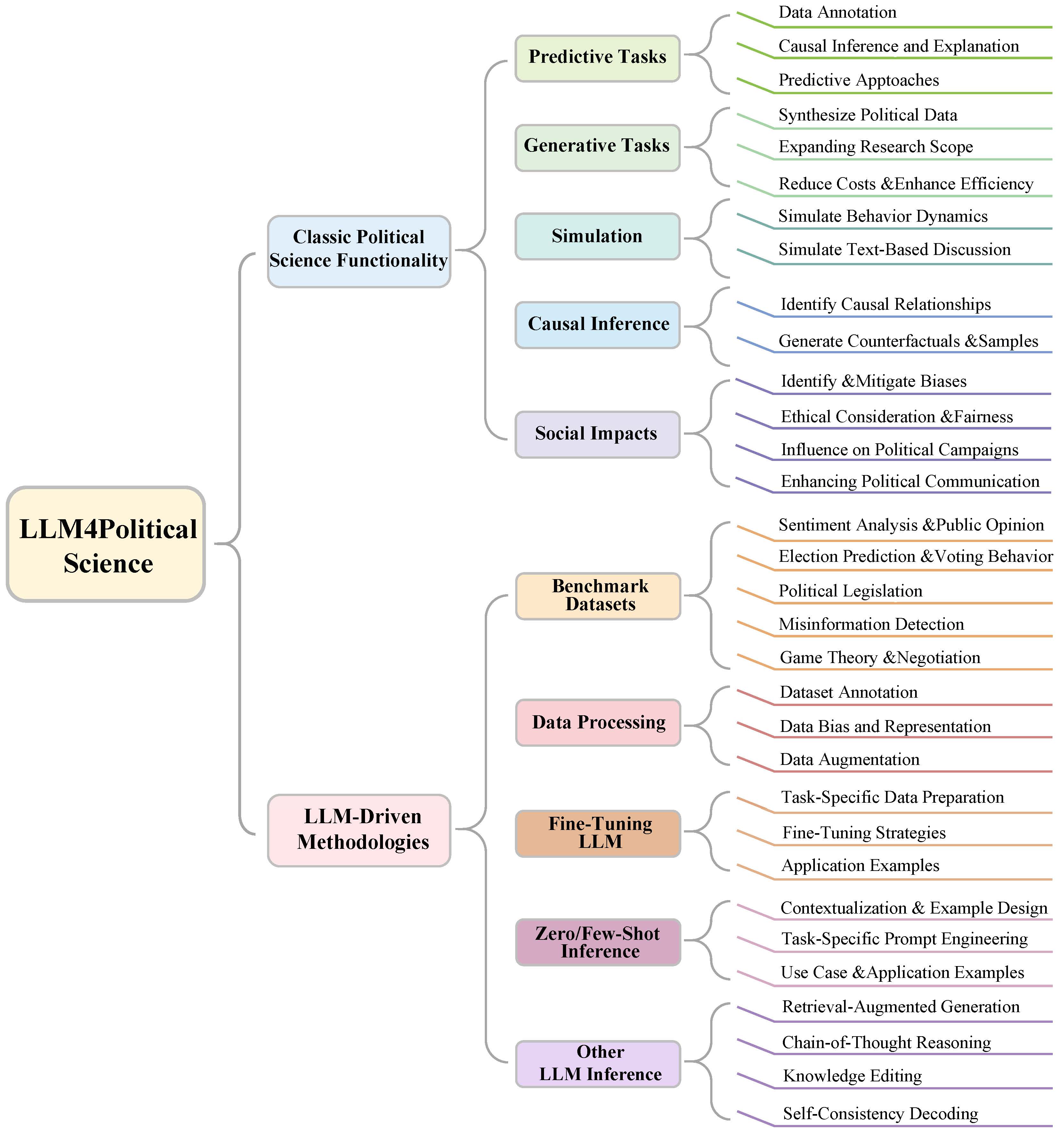
LLMs are transforming political science research by enhancing predictive, generative, simulation, and causal inference tasks while addressing societal and ethical considerations. This framework expands traditional applications by incorporating simulations to model human-like behaviors and causal inference to uncover underlying mechanisms in political phenomena.
Predictive tasks, like forecasting election outcomes or analyzing voter behavior, are essential in political science but often involve time-consuming manual efforts. Thanks to advancements in large language models (LLMs), these tasks are now faster, more efficient, and scalable. LLMs excel in automating data annotation, outperforming manual methods and even domain experts in analyzing political ideology, fake news, sentiment, and other political texts. For example, GPT-3 has been used to analyze U.S. corporate feedback on climate regulations, while GPT-4 has processed public opinions in New Zealand with impressive accuracy. Beyond English-speaking contexts, models like Llama have analyzed European Parliament debates, and Claude-1.3 has categorized survey responses for political studies in the UK. Tailored frameworks, such as PoliPrompt, take this further by fine-tuning LLMs for political science, enabling tasks like classifying topics, analyzing campaign sentiment, and detecting political stances with added precision. While LLMs are transforming predictive tasks, challenges remain, such as addressing cultural nuances and biases in datasets. However, ongoing improvements promise to make these tools even more impactful for political research.

Generative tasks in political science leverage LLMs to create synthetic data, simulate scenarios, and augment incomplete datasets, addressing challenges like data scarcity, privacy concerns, and high costs of traditional methods. LLMs generate realistic proxies for missing data, enabling analysis of topics such as public sentiment on immigration, healthcare, and climate policies, or simulating voter behavior and campaign strategies. These advancements broaden research opportunities by providing efficient, cost-effective solutions where conventional approaches fall short. Beyond data synthesis, LLMs expand research scope by analyzing complex variables, such as government policy biases or ideological dynamics. They process extensive political text corpora, revealing patterns in sentiment, discourse, and public concerns at scale. Applications like coding open-ended survey responses showcase their ability to handle nuanced qualitative data efficiently. However, challenges remain in ensuring the reliability and neutrality of synthetic data. Biases and limitations in interpreting results in nuanced political contexts must be addressed to maximize LLMs’ potential in political research.
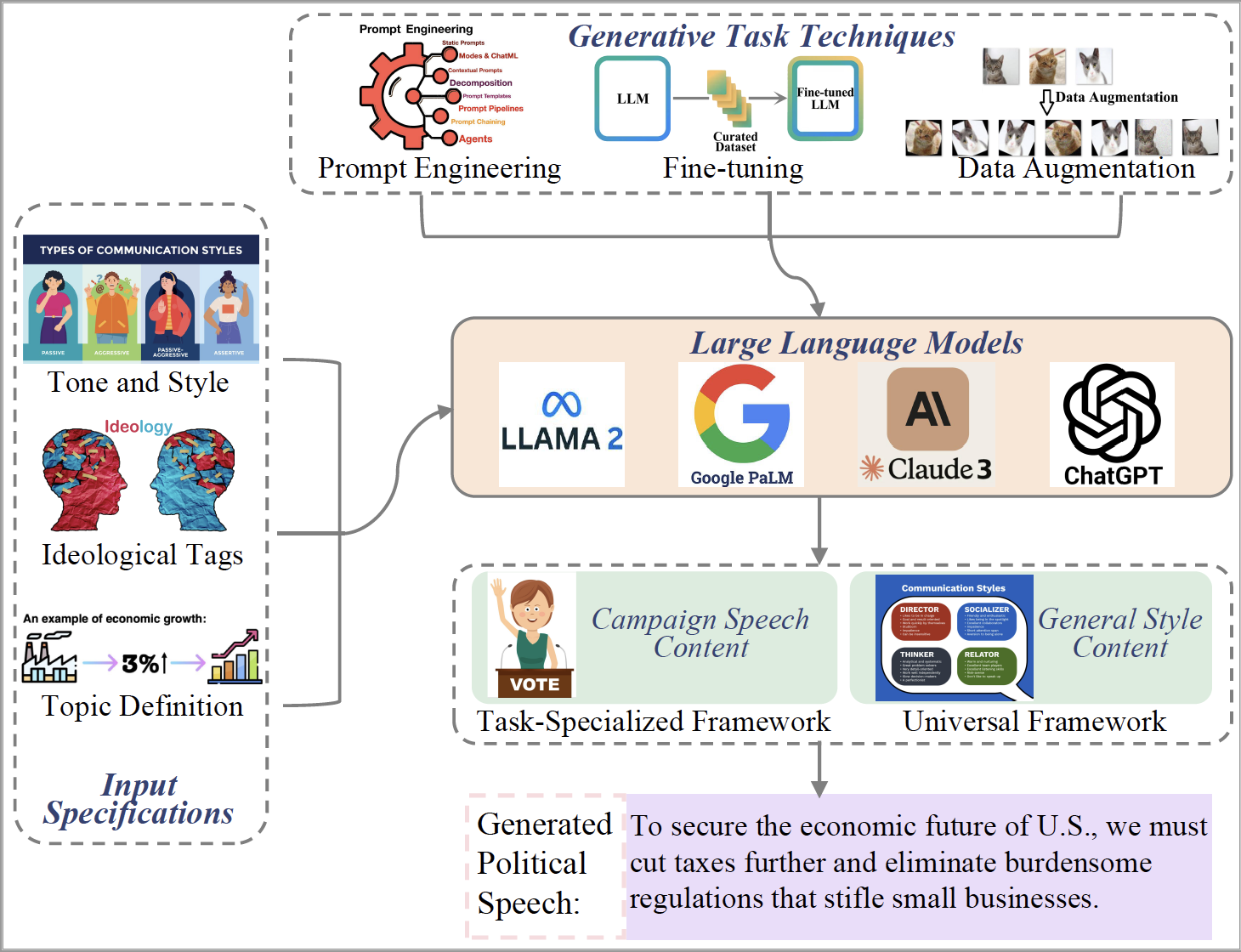
Simulation agents in political science leverage LLMs to model complex behaviors, decisions, and interactions, offering a dynamic way to study political processes like governance, negotiation, and conflict resolution. Unlike generative tasks, which focus on creating synthetic data to address scarcity, simulation tasks emphasize modeling interactions within environments to study strategies and evolving systems. Applications of simulation agents can be divided into two categories: simulating behavior dynamics and text-based discussions. Behavior dynamics simulations explore political processes like conflict resolution, governance under scarcity, and opinion polarization. For example, studies have modeled international diplomacy, ideological conflicts, and social contract theories using LLM agents. Text-based simulations focus on political discourse, such as U.S. Senate debates, multi-party coalition negotiations, and global diplomacy, where agents interact through dialogue to simulate decision-making and alliance-building. Despite their transformative potential, challenges include mitigating biases from training data, addressing ethical concerns, and managing the high computational costs of large-scale simulations. These issues highlight the need for robust validation and ethical safeguards. LLM-driven simulations offer new opportunities for understanding political interactions, making them a powerful tool for political science research.
LLM explainability ensures that outputs are interpretable and transparent, fostering trust in politically sensitive applications. In political science, causal inference, which identifies cause-and-effect relationships, is essential for understanding policies, voter behavior, and societal dynamics. LLMs offer new tools for causal inference by detecting patterns, modeling causal relationships, and generating counterfactual scenarios to explore “what-if” conditions. For example, they can simulate experimental data, assess treatment effects, and evaluate causal methods like propensity score matching. Explainability tools, such as attention mechanisms and prompt engineering, further enhance the transparency of LLM-driven causal analysis, especially in politically sensitive contexts. Despite their strengths, such as immunity to carryover effects and the ability to model causal graphs, LLMs face significant limitations. Critics argue that LLMs often recite learned patterns without true causal understanding, raising concerns about their reliability for causal reasoning. Unpredictable failure modes, biases embedded in training data, and ethical challenges in politically sensitive settings further complicate their use. However, with ongoing research and improvements, LLMs hold great promise for advancing explainability and causal inference in political science, offering tools for exploring cause-and-effect relationships and enabling more robust and transparent analyses.
Large Language Models (LLMs) have transformative potential but raise significant ethical concerns due to biases in their training data. These biases can amplify societal inequalities, suppress marginalized voices, and reinforce stereotypes. Studies reveal that LLMs often align with specific ideological perspectives, such as progressive views, and depict socially subordinate groups as homogeneous, mirroring societal biases. Cross-lingual biases further broaden these concerns, highlighting the widespread influence of LLM-generated outputs on public discourse and decision-making. Efforts to mitigate biases focus on improving training data, refining algorithms, and applying fairness constraints. Post-processing filters, such as those demonstrated by Rozado, neutralize political biases, while frameworks like CommunityLM balance partisan worldviews. Techniques like “moral mimicry” align LLM outputs with diverse ethical frameworks, promoting inclusivity. Biases in LLMs have far-reaching impacts, shaping user perceptions, perpetuating inequalities, and hindering impartiality in global discourse. Addressing these challenges requires awareness, accountability, and transparency. Researchers must prioritize robust methodologies for bias mitigation to ensure fairness, inclusivity, and ethical deployment of LLMs in sensitive domains like politics and social sciences. These efforts are crucial to developing LLMs as tools that support equitable and responsible applications.
LLMs are transforming the political landscape by enhancing campaign strategies, improving political communication, and democratizing information access. They enable hyper-personalized voter targeting and simplify complex political content, fostering greater public understanding and engagement. By breaking down barriers to political knowledge, LLMs promote inclusivity and active civic participation. However, their societal deployment raises ethical risks, including the potential for misinformation and biased content that can manipulate public opinion or undermine democratic processes. The realistic but misleading content generated by LLMs underscores the need for robust governance frameworks and safeguards. To balance their benefits and risks, efforts must focus on responsible deployment, transparency, public awareness, and misinformation prevention. By addressing these challenges, LLMs can be harnessed to create a more equitable, informed, and participatory political environment.
We conducted a case study based on the 2016 American National Election Studies (ANES) benchmark dataset, the results are demonstrated in the video below. The case study aimed to address two key aspects: (1) the biases displayed by different LLMs during voting simulation, and (2) the quality of LLM-generated political features compared to the original dataset, assessing their effectiveness for feature generation tasks in political science. We evaluated four large language models (LLMs) with varying parameter sizes: two commercial models, GPT-4o and GPT-4o-mini, and two open-source models, Llama 3.1 8-B and Llama 3.1-70B. ANES dataset was selected for its comprehensive demographic, political ideology, and religious data, which provided a robust basis for analyzing the potential biases and generative capabilities of LLMs in political science context.
Computational approaches for advancing LLMs in political science focus on developing specialized methods such as fine-tuning, zero/few-shot learning, and prompt engineering to adapt LLMs for political tasks. These techniques enhance the performance of LLMs in analyzing political texts, modeling ideological dynamics, and generating insights for policy and governance studies.
Benchmark datasets play a critical role in advancing LLM applications in political science, covering areas such as sentiment analysis, election prediction, legislative summarization, misinformation detection, and conflict resolution. These datasets ensure that LLM outputs align with real-world political and social contexts, enabling comprehensive evaluation and practical applications. Here we conclude existing benchmark datasets.
| Benchmark Datasets | Application Domain | Evaluation Criteria |
|---|---|---|
| OpinionQA Dataset | Sentiment Analysis & Public Opinion | Ability to answer 1,489 questions |
| PerSenT | Sentiment Analysis & Public Opinion | Performance on 38,000 annotated paragraphs |
| GermEval-2017 | Sentiment Analysis & Public Opinion | Accuracy on 26,000 annotated documents |
| Sentiment Analysis & Public Opinion | Analysis of 5,802 annotated tweets | |
| Bengali News Comments | Sentiment Analysis & Public Opinion | Performance on 13,802 Bengali news texts |
| Indonesia News | Sentiment Analysis & Public Opinion | Sentiment analysis on 18,810 news headlines |
| U.S. Senate Returns 2020 | Election Prediction & Voting Behavior | Prediction accuracy on 759,381 data points |
| U.S. House Returns 2018 | Election Prediction & Voting Behavior | Analysis of 836,425 data points |
| State Precinct-Level Returns 2018 | Election Prediction & Voting Behavior | Analysis of 10,527,463 data points |
| 2008 American National Election | Election Prediction & Voting Behavior | Analysis of 2,322 pre-election and 2,102 post-election surveys |
| U.S. President 1976–2020 | Election Prediction & Voting Behavior | Analysis of 4,288 data points |
| BillSum | Political Legislation | Summarization of 33,422 U.S. Congressional bills |
| CaseLaw | Political Legislation | Analysis of 6,930,777 state and federal cases |
| DEU III | Political Legislation | Performance on 141 legislative proposals and 363 controversial issues |
| PolitiFact | Misinformation Detection | Detection across six integrated datasets |
| GossipCop | Misinformation Detection | Detection across ten integrated datasets |
| Misinformation Detection | Classification of 4,488 fake news and 4,640 real news items | |
| SciNews | Misinformation Detection | Detection in 2,400 scientific news stories |
| UCDP | Game Theory & Negotiation | Analysis of armed conflicts and peace agreements |
| PNCC | Game Theory & Negotiation | Data on peace agreements and conflict resolution |
| WebDiplomacy | Game Theory & Negotiation | Analysis of 12,901,662 messages exchanged between players |
Dataset preparation for LLMs in political science involves collecting, annotating, and augmenting political data from sources like speeches, legislative texts, and surveys, ensuring balance across ideologies and demographics. Strategies include manual and automated annotation, preprocessing, and generating synthetic datasets to address data scarcity and enhance LLM performance in tasks like debiasing, legislative interpretation, and election prediction.
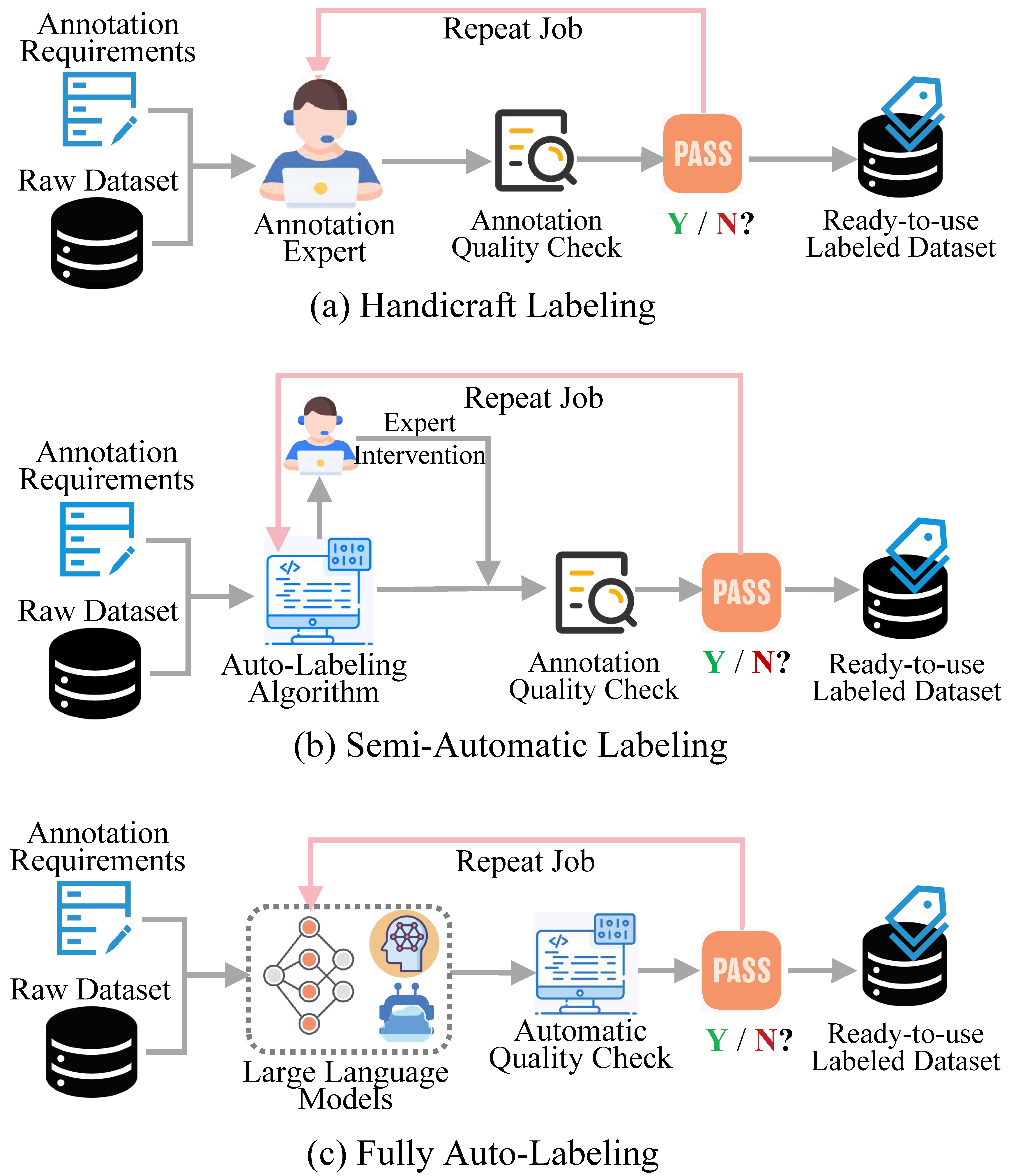
Fine-tuning LLMs for political science involves adapting pre-trained models to specialized tasks, such as legislative summarization, using domain-specific datasets like BillSum. This process includes data preprocessing, parameter-efficient fine-tuning techniques like LoRA, and prompt engineering to ensure the model generates accurate, concise, and accessible outputs. Fine-tuned models can effectively summarize legislative documents, generalize across legislative domains, and enhance understanding of complex legal texts for diverse audiences.
Zero-Shot Learning (ZSL) allows LLMs to perform tasks like sentiment analysis in political science without task-specific training, leveraging pre-existing linguistic knowledge. By using carefully crafted prompts that provide context and task instructions, ZSL enables LLMs to classify sentiment, ideology, and stances on political statements efficiently. This approach is particularly valuable for analyzing public opinion during events like elections, as it eliminates the need for annotated datasets while maintaining flexibility and accuracy in real-world political applications.
Few-shot learning leverages minimal labeled examples embedded in prompts to enable LLMs to perform specialized political science tasks, bridging the gap between zero-shot inference and full fine-tuning. By carefully selecting diverse and context-rich examples, few-shot learning enhances tasks like fake news detection, public opinion analysis, and policy stance classification, making it a flexible, cost-effective approach for nuanced political discourse and real-time analysis in data-scarce environments.
Explore advanced techniques that enhance LLM inference in political science applications, including Retrieval-Augmented Generation (RAG) for integrating real-time data, Chain-of-Thought Reasoning (CoT) for step-by-step logical analysis, Knowledge Editing for updating model knowledge dynamically, and Contrastive Decoding for generating more consistent and reliable outputs. These methods bring greater precision, adaptability, and depth to tasks like policy analysis, public opinion tracking, and complex political discourse.
This case study evaluates political bias and feature generation quality using four publicly available general LLMs (GPT-4o, GPT-4o-mini, Llama 3.1-8B, Llama 3.1-70B) and their variants with the 2016 ANES benchmark dataset. We quantitatively evaluate: (1) voting simulation bias, and (2) feature generation quality. The results highlight:
We evaluated four large language models (LLMs) with varying parameter sizes: two commercial models, GPT-4o and GPT-4o-mini, and two open-source models, Llama 3.1 8-B and Llama 3.1-70B. The hardware configurations were tailored to meet the computational requirements of each model. For GPT-4o and GPT-4o-mini, experiments were conducted on a GPU server equipped with an AMD EPYC Milan 7763 processor, 1 TB of DDR4 memory, 15 TB SSD storage, and 6 NVIDIA RTX A6000 GPUs. For Llama 3.1 models, a node with 8 NVIDIA A100 GPUs (each with 40 GB of memory), dual AMD Milan CPUs, 2 TB of RAM, and 1.5 TB of local storage was utilized.
Larger models like GPT-4o and Llama 3.1-70B produced outputs closely aligned with actual voting distributions, particularly when political features were included. Smaller models showed skewed results favoring the winning party of 2016 (Republican), indicating their limitations in bias mitigation.
Larger models generated political ideologies that closely matched the ground truth, while smaller models failed to reflect diverse political perspectives, often defaulting to alignments with the 2016 winning party.
The study underscores the role of political features in reducing bias and the superior generation capabilities of larger models.
The integration of Large Language Models (LLMs) into political science offers immense potential but also presents significant challenges. A primary issue is adapting LLMs to political tasks that require nuanced contextual understanding of concepts like ideology and policy framing. Future research should focus on domain-specific fine-tuning, hybrid human-AI workflows, and modularized pipelines, which divide complex tasks like election forecasting into sub-components (e.g., data preprocessing, regional analysis, and predictive modeling). Retrieval-Augmented Generation (RAG) can further enhance these pipelines by dynamically incorporating real-time data, ensuring outputs remain contextually relevant.
Data scarcity is another major obstacle, as political science lacks large-scale, high-quality datasets tailored to tasks like election modeling or policy analysis. To address this, researchers can develop domain-specific datasets from political speeches or legislative records and use LLMs for synthetic data generation to simulate rare events or expand data diversity. Validation protocols must ensure the reliability and neutrality of these datasets, while partnerships with public institutions can provide better access to valuable data.
Bias and fairness remain critical challenges, as LLMs can reflect and amplify biases in training data. Techniques like knowledge editing and counterfactual data augmentation can mitigate these biases by balancing underrepresented perspectives. Additionally, Explainable AI (XAI) can enhance transparency by clarifying the reasoning behind model predictions, fostering trust in politically sensitive applications.
Hallucinations—where LLMs generate plausible but inaccurate outputs—pose risks in tasks like legislative summarization or policy analysis. Strategies such as feature attribution, causal modeling, and validation checkpoints can address this issue, ensuring outputs are grounded in factual data and aligned with empirical evidence.
Lastly, democratizing access to political knowledge is essential for enabling broader public engagement. LLM-powered tools can simplify complex political language, provide multilingual support, and incorporate ethical AI principles to make political information accessible, accurate, and inclusive. To advance computational political science, novel evaluation metrics should be developed, assessing outputs for policy relevance, electoral impact, legislative influence, and fairness, ensuring models align with real-world political demands.
We deeply thank our collaborators from the following academic and industrial institutions:
@article{Li2024political-llm,
title={Political-LLM: Large Language Models in Political Science},
author={Lincan Li, Jiaqi Li, Catherine Chen, Fred Gui, Hongjia Yang, Chenxiao Yu,
Zhengguang Wang, Jianing Cai, Junlong Aaron Zhou, Bolin Shen, Alex Qian,
Weixin Chen, Zhongkai Xue, Lichao Sun, Lifang He, Hanjie Chen, Kaize Ding,
Zijian Du, Fangzhou Mum, Jiaxin Pei, Jieyu Zhao, Swabha Swayamdipta, Willie Neiswanger,
Hua Wei, Xiyang Hu, Shixiang Zhu, Tianlong Chen, Yingzhou Lu, Yang Shi, Lianhui Qin,
Tianfan Fu, Zhengzhong Tu, Yuzhe Yang, Jaemin Yoo, Jiaheng Zhang, Ryan Rossi, Liang Zhan,
Liang Zhao, Emilio Ferrara, Yan Liu, Furong Huang, Xiangliang Zhang, Lawrence Rothenberg,
Shuiwang Ji, Philip S. Yu, Yue Zhao, Yushun Dong},
journal={arXiv preprint arXiv:2412.xxxxx},
year={2024}
}